SB Intuitions の 岡 照晃、李 凌寒、水本 智也、柴田 知秀 です。 本記事では Sarashina の性能評価について解説します。
Sarashina は SB Intuitions で開発している日本語の大規模言語モデル(Large Language Model; LLM)です。
LLM の学習は一般に事前学習のステップとチューニングのステップから成ります。 事前学習では、大規模テキストを用い、与えられたテキストの続きを予測していく次単語予測の性能が上がるように学習を行います。 チューニングでは、ユーザ発話とシステム応答がペアになったチューニング用データから対話的にタスクを遂行する能力を獲得します。

先月、以下の 5つの事前学習モデルを公開しました。 モデルの学習に関する詳細はこちらのブログ記事をご覧ください。
本ブログでは事前学習モデルの評価の詳細を説明します。
事前学習モデルの評価では、次単語予測の能力で自然言語処理(Natural Language Processing; NLP)のタスクがどれくらい解けるかを調べます。 プレスリリース では Sarashina を含めた事前学習モデルの平均性能を掲載しました。 平均性能は後述する 5つの評価用データセットの性能の平均をとっています。 平均性能はモデルの性能を把握する一つの指標となりますが、 評価用データセットごとにモデル性能のばらつきが異なるため、平均性能のみで議論するのは誤解を招きかねません。 実情を正しく把握するためには評価用データセットごとの性能を分析する必要があります。 またタスク設計の仕方ひとつで評価している側面は変わります。 SB Intuitions では評価用データセットごとに評価方法を見直し、モデルのどういった能力を測るのか、タスク設定から再検討しました。

本記事の図表中に記載の値は 2024/07/12 現在での当社調べです。 モデルがアップデートされている場合もありますのでご注意ください。
比較した事前学習モデル
今回比較したのは以下の日本語事前学習モデルです。 2024/07/12 現在、62 の事前学習モデルを比較評価していますが表示の都合上、 Sarashina と同じフルスクラッチの日本語事前学習モデルは基本的に掲載し、 継続事前学習モデルは性能上位に限定しています。 また事前学習モデルはチューニングを行う前のモデルですので、 例えば Swallow-70b-instruct-v0.1 のようなチューニング済みのモデルとは直接比較できません。
| モデル名 | 事前学習の方法 | 開発機関 |
|---|---|---|
| calm2-7b | フルスクラッチ | サイバーエージェント |
| RakutenAI-7B | Mistral-7B-v0.1 からの継続事前学習 | 楽天 |
| Swallow-7b-plus | Llama-2-7b からの継続事前学習 | 東京工業大学 |
| stockmark-13b | フルスクラッチ | Stockmark |
| plamo-13b | フルスクラッチ | Preferred Networks |
| llm-jp-13b-v2.0 | フルスクラッチ | 国立情報学研究所(NII) |
| nekomata-14b | Qwen-14B からの継続事前学習 | rinna |
| Swallow-13b | Llama-2-13b からの継続事前学習 | 東京工業大学 |
| karakuri-lm-70b-v0.1 | Llama-2-70b からの継続事前学習 | KARAKURI |
| Swallow-70b | Llama-2-70b からの継続事前学習 | 東京工業大学 |
上記のモデルはすべて 2024/07/12 現在、Hugging Face にて公開されている最新のバージョンをダウンロードして使用しています。
使用したデータセットと評価ツール
今回使用した評価用データセットは以下の 5つです。
- AI王(自由記述式質問応答)[鈴木+, 2020]
- JCommonsenseQA(選択式質問応答)[Kurihara+, 2022](JComQA と略記)
- JEMHopQA(自由記述式質問応答、選択式質問応答、2値分類)[石井+, 2023]
- NIILC-QA(自由記述式質問応答)[関根, 2003](NIILC と略記)
- JSQuAD(機械読解)[Kurihara+, 2022]
今回の評価では、日本語の質問応答・読解に関するデータセットを集めました。 AI王はクイズ問題が題材のコンペティションで配布されたデータセットです。 日本に関する知識を問う問題を広範なトピックから多数収録しており、SB Intuitions ではベンチマークとして重視しています。 残り 4つは東京工業大学の Swallow や 国立情報学研究所の LLM-jp が公開している比較実験でも使われている一般的な質問応答データセットです。
評価用ツールには llm-jp-eval や lm-evaluation-harness といった実装がありますが、 既存の実装は利用せず、SB Intuitions 内部で開発したツール flexeval を用いて、 各データセットで測りたい問題解決能力を引き出す方法を検討しています。 その結果が以下の表です。 プレスリリースにも掲載した平均性能はこの 5つのデータセットスコアの平均値です。 本記事の結果と、他機関が公開している評価結果はデータセットが同じであっても設定が異なり直接比較できないことに注意して下さい。
データセットごとのモデル性能一覧
| モデル | 平均 | AI王 | JComQA | JEMHopQA | NIILC | JSQuAD |
|---|---|---|---|---|---|---|
| calm2-7b | 54.36 | 59.40 | 55.23 | 47.01 | 40.74 | 69.43 |
| RakutenAI-7B | 60.80 | 47.60 | 87.58 | 47.01 | 38.27 | 83.52 |
| Sarashina1-7B | 61.35 | 69.70 | 69.53 | 45.30 | 44.44 | 77.78 |
| Swallow-7b-plus | 67.99 | 74.30 | 83.38 | 52.14 | 48.77 | 81.34 |
| Sarashina2-7B | 70.12 | 73.30 | 86.06 | 55.56 | 50.00 | 85.66 |
| stockmark-13b | 42.91 | 73.40 | 25.65 | 17.95 | 29.01 | 68.53 |
| plamo-13b | 43.82 | 43.40 | 35.12 | 41.88 | 30.25 | 68.46 |
| llm-jp-13b-v2.0 | 55.30 | 61.00 | 50.49 | 47.01 | 41.36 | 76.63 |
| Sarashina1-13B | 65.12 | 77.10 | 77.12 | 44.44 | 48.77 | 78.16 |
| nekomata-14b | 71.95 | 71.20 | 93.74 | 57.26 | 47.53 | 90.03 |
| Swallow-13b | 73.77 | 77.90 | 89.01 | 62.39 | 51.23 | 88.34 |
| Sarashina2-13B | 76.20 | 80.80 | 89.90 | 64.96 | 56.79 | 88.56 |
| karakuri-lm-70b-v0.1 | 68.28 | 66.60 | 89.90 | 52.99 | 43.21 | 88.68 |
| Sarashina1-65B | 74.16 | 87.10 | 84.09 | 60.68 | 53.70 | 85.21 |
| Swallow-70b | 82.40 | 87.40 | 95.26 | 80.34 | 58.02 | 91.00 |
ここからのセクションでは各データセットの評価設定を詳しく説明していきます。
AI王
AI王はクイズ問題の質問応答データセットです。 第2回コンペティション開発データ(1,000問)を拡張して使っています。 AI王には例えば以下のような問題があります。
1642年にクロムウェルを指導者として起こったイギリスの市民革命のことを、何革命という?
事前学習モデルは与えられたテキストの続きを予測して生成するモデルなので、この問題を解かせたい場合、
例えば以下のように答えは「を問題末尾に付けて入力し、その続きとしてクイズの答えが生成されると期待します。
1642年にクロムウェルを指導者として起こったイギリスの市民革命のことを、何革命という?答えは「
上記の入力に対し、Sarashina1-7B は期待通りの生成を行い、生成結果も正解でした(評価時には閉じかぎ括弧は削除しています)。
ピューリタン革命」わかりやすさのため、モデルが生成する部分は青字で示しています。
文字列正規化と別解の追加
前述の問題に対し、事前学習モデルは以下のような生成をする可能性もあります。
- ピューリタン革命
- 清教徒革命
1つ目はカタカナ部分が半角カタカナですが、間違いではありません。 2つ目も一見不正解ですが、Wikipedia の清教徒革命の項目には「ピューリタン革命または清教徒革命」とあります。 つまり「清教徒革命」は「ピューリタン革命」の同義語で、間違いではありません。
これらを単純な文字列比較で不正解にしないため、生成された文字列の正規化と、別解の追加を行いました。 文字列の正規化は AI王のコンペティションで用意された文字列正規化を使用しました。 また正規化だけでは対応できない「清教徒革命」のような生成はあらかじめ別解として正解のリストに記述しました。
評価結果
評価尺度は exact match(文字列が完全一致か否かの正解率)を採用しました。 文字単位で部分一致が考慮できる char F1 も使用できますが、文字列正規化や別解追加で表記揺れに対応したこともあり、 厳密な方法を採用しました。 例えば char F1 ですと「フランス革命」のような誤った生成にも部分点を付けますが、exact match ならば 0点です。
先に示したデータセットごとのモデル性能一覧の AI王の列が評価結果です。 モデルサイズ 7b 規模では Swallow-7b-plus が最も高いスコアですが、13b規模ならば Sarashina2-13B が最も高いスコアです。 70b規模になると Sarashina1-65B と僅差で Swallow-70b が最も高いスコアです。
AI王スコアを棒グラフで表示

抜粋ですが以下に文字列正規化と別解追加の効果を示します。 モデル性能の優劣関係はほぼ変わりませんが、どのモデルでも 5〜7ポイントのスコアの上昇があります。 全 1,000問ですから、不正解と判定されていたモデル出力が、実は正解とみなせるものだった場合が 50〜70問もあったとわかります。
| モデル | 文字列正規化・別解追加なし | 文字列正規化・別解追加あり |
|---|---|---|
| Sarashina1-7B | 64.40 | 69.70 |
| Swallow-7b-plus | 68.10 | 74.30 |
| Sarashina2-7B | 68.10 | 73.30 |
| Sarashina1-13B | 71.70 | 77.10 |
| Swallow-13b | 71.80 | 77.90 |
| Sarashina2-13B | 75.70 | 80.80 |
| Sarashina1-65B | 79.40 | 87.10 |
| Swallow-70b | 80.90 | 87.40 |
比較表のフルサイズを表示
| モデル | 文字列正規化・別解追加なし | 文字列正規化・別解追加あり |
|---|---|---|
| calm2-7b | 54.60 | 59.40 |
| RakutenAI-7B | 41.60 | 47.60 |
| Sarashina1-7B | 64.40 | 69.70 |
| Swallow-7b-plus | 68.10 | 74.30 |
| Sarashina2-7B | 68.10 | 73.30 |
| stockmark-13b | 67.20 | 73.40 |
| plamo-13b | 39.60 | 43.40 |
| llm-jp-13b-v2.0 | 55.50 | 61.00 |
| Sarashina1-13B | 71.70 | 77.10 |
| nekomata-14b | 65.80 | 71.20 |
| Swallow-13b | 71.80 | 77.90 |
| Sarashina2-13B | 75.70 | 80.80 |
| karakuri-lm-70b-v0.1 | 60.60 | 66.60 |
| Sarashina1-65B | 79.40 | 87.10 |
| Swallow-70b | 80.90 | 87.40 |
再現性の確保(1)
LLM の生成結果は生成時の設定や実行環境によって変わります。それでもできる限り再現性を保つため、評価の際は以下を行なっています。
- Greedy Search: サンプリングを使わず、最も確率の高い予測を繰り返す。
- batch_size=1: 複数の問題を同時並行で解くこともできるがランダム性も生じるため、常に 1問ずつ解いていく。
JCommonsenseQA
JCommonsenseQA は質問と選択肢が提示され、選択肢の中から正解を選ぶタスクです。 評価には valid-v1.1 を使用しています(1,119問)。
llm-jp-eval v.1.0.0 の JCommonsenseQA は各選択肢の先頭に番号があり、その番号 1文字を生成するタスク設定です。
以下の例の場合、正解が「マザーボード」であるため、### 回答:までが与えられた上で「2」の生成が求められます。
AI王のときと同様、わかりやすさのため、モデルが生成する部分を青字で示しています。
### 入力:
質問:電子機器で使用される最も主要な電子回路基板の事をなんと言う?
選択肢:0.掲示板,1.パソコン,2.マザーボード,3.ハードディスク,4.まな板
### 回答:
2番号を 1つ生成するだけのタスクですが、選択肢の中から直接回答を選ぶより 1つ動作が必要な設定です。 「選択肢から正しく正解を特定」できても「正解選択肢の番号を生成する」までできないと不正解です。
モデルのどういった能力を評価したいかによりますが、 ここでは「選択肢の中から正解を選んで答える能力」をより直接的に測ることを目的に、 下記のように提示された選択肢の文字列で回答するタスクに変更しました。 上記の例の場合、与えられた選択肢中から「マザーボード」を選び、回答として生成します。
### 入力:
質問:電子機器で使用される最も主要な電子回路基板の事をなんと言う?
選択肢:掲示板,パソコン,マザーボード,ハードディスク,まな板
### 回答:
マザーボードまた事前学習モデルはテキストの続きを予測する学習しかしていないので、
### 回答:の後に「選択肢の中から正解を選んで答える」動作を教える必要があります。
教えなくてもある程度、回答を生成することはできますが、本来解かせたい問題の前に教示用の問題を置くことによって、求める回答を生成する能力を上げることができます。
これを few-shot learning*2 と言います。
llm-jp-eval v.1.0.0 に倣い、以下の 4問を 4-shot事例として固定しました。
JCommonsenseQAで使用した 4-shot事例
以下はタスクを説明する指示と、追加の背景情報を提供する入力の組み合わせです。要求を適切に満たす回答を書いてください。 ### 指示 質問と回答の選択肢を入力として受け取り、選択肢から回答を選択してください。回答の他には何も含めないことを厳守してください。 ### 入力: 質問:主に子ども向けのもので、イラストのついた物語が書かれているものはどれ? 選択肢:世界,写真集,絵本,論文,図鑑 ### 回答: 絵本 ### 入力: 質問:未成年者を監護・教育し,彼らを監督し,彼らの財産上の利益を守る法律上の義務をもつ人は? 選択肢:浮浪者,保護者,お坊さん,宗教者,預言者 ### 回答: 保護者 ### 入力: 質問:数字の1を表すときに使う体は? 選択肢:胸,肉球,背中,人差し指,親指 ### 回答: 人差し指 ### 入力: 質問:火を起こすとあらわれるもくもくするものは? 選択肢:歯の変色,ガス,中毒,爆発,煙 ### 回答: 煙
評価結果
先に示したデータセットごとのモデル性能一覧の JComQA の列が JCommonsenseQA の exact match スコアです。 継続事前学習モデルのベースとなっているモデル(Llama-2 や Qwen など)の性能がこのタスクで元々高いことから、 モデルサイズ 7b 規模では mistral ベースの RakutenAI-7b、13b 規模ならば Qwen ベースの nekomata-14b、70b 規模では Llama2 ベースの Swallow-70b が最も高い性能です。 しかし Sarashina2 も見劣りしないスコアで 2位の性能を達成しています。
JCommonsenseQA のスコアを棒グラフで表示
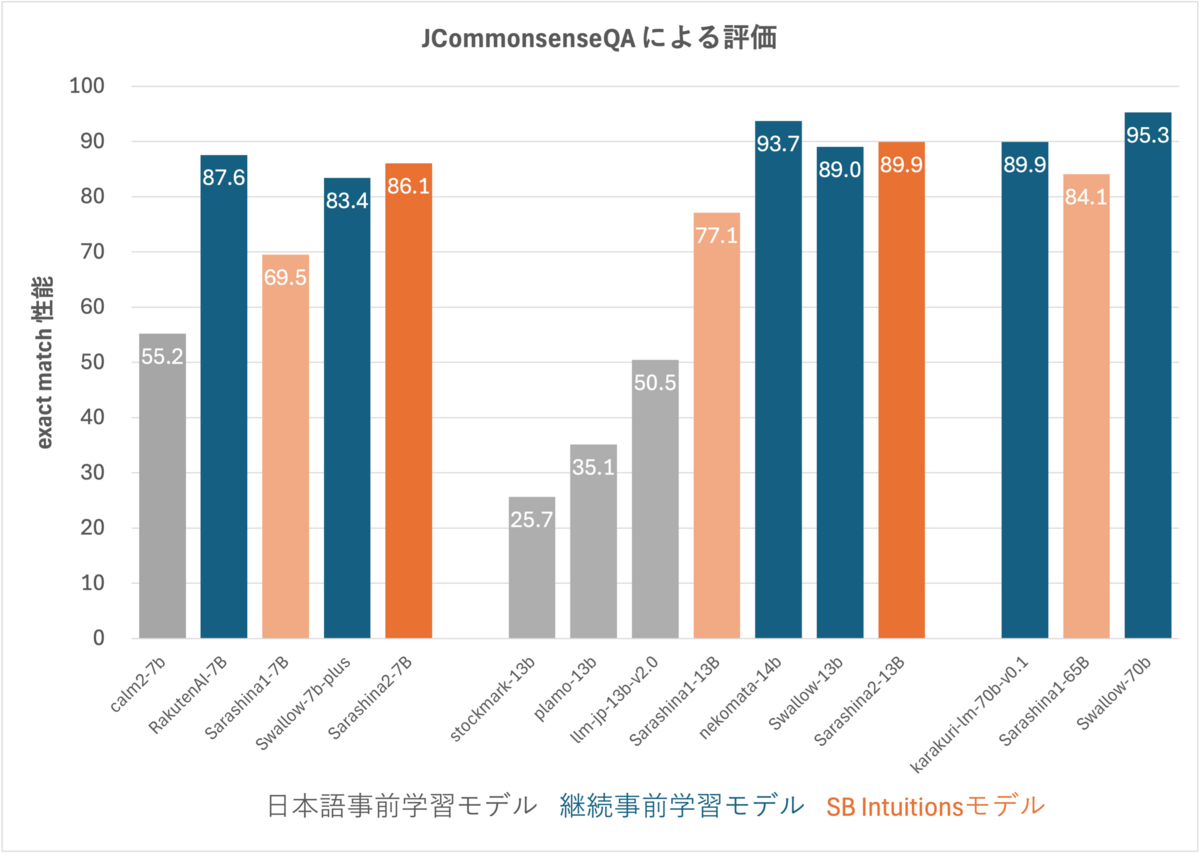
以下の表は選択肢を番号で答える設定と文字列で直接答える設定でスコアを比較した抜粋です。 番号回答設定から文字列回答設定に変更することでスコアが下がったモデルはありませんでした。 番号回答設定でスコアが極端に低いモデルも、文字列回答では他のモデルと近いスコアになります。 そのため正解がわかっていなかったのではなく、文字列と選択肢番号の対応をとる能力が弱いと考えられます。 ただし、選択肢番号で回答する設定でも正しく回答できるべきという立場もあり、問題設定の優劣を主張するわけではありません。
| モデル | 選択肢番号で回答 | 選択肢文字列で回答 |
|---|---|---|
| RakutenAI-7B | 87.04 | 87.58 |
| Sarashina1-7B | 24.13 | 69.53 |
| Swallow-7b-plus | 55.94 | 83.38 |
| Sarashina2-7B | 74.80 | 86.06 |
| llm-jp-13b-v2.0 | 22.07 | 50.49 |
| Sarashina1-13B | 38.16 | 77.12 |
| nekomata-14b | 91.33 | 93.74 |
| Sarashina2-13B | 87.31 | 89.90 |
| Sarashina1-65B | 67.29 | 84.09 |
| Swallow-70b | 93.30 | 95.26 |
比較表のフルサイズを表示
| モデル | 選択肢番号で回答 | 選択肢文字列で回答 |
|---|---|---|
| calm2-7b | 21.98 | 55.23 |
| RakutenAI-7B | 87.04 | 87.58 |
| Sarashina1-7B | 24.13 | 69.53 |
| Swallow-7b-plus | 55.94 | 83.38 |
| Sarashina2-7B | 74.80 | 86.06 |
| stockmark-13b | 22.07 | 25.65 |
| plamo-13b | 23.06 | 35.12 |
| llm-jp-13b-v2.0 | 22.07 | 50.49 |
| Sarashina1-13B | 38.16 | 77.12 |
| nekomata-14b | 91.33 | 93.74 |
| Swallow-13b | 78.64 | 89.01 |
| Sarashina2-13B | 87.31 | 89.90 |
| karakuri-lm-70b-v0.1 | 85.43 | 89.90 |
| Sarashina1-65B | 67.29 | 84.09 |
| Swallow-70b | 93.30 | 95.26 |
再現性の確保(2)
few-shot事例の固定: 再現性確保の観点から、我々の評価では教示用の質問は固定し、教示の差異で生成が変化しないようにしている。 これには正解/不正解の原因をランダムな few-shot事例の当たり外れで考察するのを避ける狙いもある。
JEMHopQA
JEMHopQA はマルチホップな推論能力を測る質問応答データセットです。
構成質問と比較質問から成り、比較質問は文字列で答える質問と YES・NO で答える質問から成ります。
他のデータセットでの呼び方と整合させて、
ここでは構成質問を自由記述式質問応答、
比較質問は順に選択式質問応答と 2値分類(YES・NO)と呼ぶことにし、
3つのサブタスクに分けて考えます。
JEMHopQA の dev_ver1.1.json (120問)をサブタスクに分けると、
自由記述式質問応答: 44問、選択式質問応答: 28問、2値分類(YES・NO): 45問です。
IPhone 11を開発した会社のCOOは誰ですか? のように時間経過によって正解が変化する質問(time_dependent フラグが False のもので、3問あります)は除外しました。
評価の際、3つのサブタスクに共通の few-shot事例を与えることも考えられますが、サブタスクごとのモデル性能を引き出すため、それぞれに対応した 4-shot事例を設定しました。
また JEMHopQA は回答のみを生成するのではなく、回答までの導出過程の生成も期待しています。 [石井+, 24] の図1、図2 に例示されている形で導出過程の生成を行なったところ、 質問の正解率が向上することがわかったので、導出過程も生成するタスク設定にしました。
以下の中の青字箇所が Sarashina2-13b が実際に行なった生成例です。
4-shot 事例の中の ### 導出: 箇所を模倣し、[石井+, 24]の図2 の比較質問の導出が実現できています。
以下はタスクを説明する指示と、追加の背景情報を提供する入力の組み合わせです。要求を適切に満たす回答を書いてください。
### 指示
質問を入力とし、回答を出力してください。回答の他には何も含めないことを厳守してください。
### 入力:
質問:孝明天皇が生涯過ごした都に以前の都から遷都があった年は?
### 導出:
(孝明天皇, 生涯を過ごした都, 平安京), (平安京, 遷都された年, 794年)
### 回答:
794年
.. [3-shot事例] ..
### 入力:
質問:奥州市と酒田市はどちらも東北地方の都市ですか?
### 導出:
(奥州市, 地方, 東北地方), (酒田市, 地方, 東北地方)
### 回答:
YES各サブタスクに設定した 4-shot事例は以下の通りです。
自由記述式質問応答で使用した 4shot事例
以下はタスクを説明する指示と、追加の背景情報を提供する入力の組み合わせです。要求を適切に満たす回答を書いてください。 ### 指示 質問を入力とし、回答を出力してください。回答の他には何も含めないことを厳守してください。 ### 入力: 質問:孝明天皇が生涯過ごした都に以前の都から遷都があった年は? ### 導出: (孝明天皇, 生涯を過ごした都, 平安京), (平安京, 遷都された年, 794年) ### 回答: 794年 ### 入力: 質問:無名塾の主宰者の誕生日の年月日は? ### 導出: (無名塾, 主宰者, 仲代達矢), (仲代達矢, 生年月日, 1932年12月13日) ### 回答: 1932年12月13日 ### 入力: 質問:川島明が所属する事務所がある都道府県は? ### 導出: (川島明, 所属事務所, 吉本興業), (吉本興業, 本社所在地, 大阪府大阪市中央区(大阪市)難波千日前) ### 回答: 大阪府 ### 入力: 質問:『99.9-刑事専門弁護士-』のSEASON Iのヒロイン役で出演した俳優の所属事務所はどこですか? ### 導出: (99.9-刑事専門弁護士-, SEASON Iのヒロイン役の出演者, 榮倉奈々), (榮倉奈々, 事務所, 研音) ### 回答: 研音
選択式質問応答で使用した 4shot事例
以下はタスクを説明する指示と、追加の背景情報を提供する入力の組み合わせです。要求を適切に満たす回答を書いてください。 ### 指示 質問を入力とし、回答を出力してください。回答の他には何も含めないことを厳守してください。 ### 入力: 質問:『仮面ライダー電王』と『あまちゃん』、放送回数が多いのはどちらでしょう? ### 導出: (仮面ライダー電王, 放送回数, 49), (あまちゃん, 放送回数, 156) ### 回答: あまちゃん ### 入力: 質問:清原果耶と森田成一で活動開始が早かったのはどちらですか? ### 導出: (清原果耶, 活動開始時, 2015年), (森田成一, 活動開始時, 2001年) ### 回答: 森田成一 ### 入力: 質問:映画『ダイ・ハード』と『デッドプール2』のうち、公開年が早いほうはどっち? ### 導出: (ダイ・ハード, 公開年, 1988年), (デッドプール2, 公開年, 2018年) ### 回答: ダイ・ハード ### 入力: 質問:漫画『テセウスの船』と『35歳の高校生』はどちらの話数が多いでしょうか? ### 導出: (テセウスの船 (漫画), 話数, 89話), (35歳の高校生, 話数, 11話) ### 回答: テセウスの船
2値分類(YES・NO)で使用した 4shot事例
以下はタスクを説明する指示と、追加の背景情報を提供する入力の組み合わせです。要求を適切に満たす回答を書いてください。 ### 指示 質問を入力とし、回答を出力してください。回答の他には何も含めないことを厳守してください。 ### 入力: 質問:『ぼくらが旅に出る理由』と『ボーン・トゥ・ラヴ・ユー』はどちらも小沢健二のシングルですか? ### 導出: (ぼくらが旅に出る理由, 企画・制作, 小沢健二), (ボーン・トゥ・ラヴ・ユー, 企画・制作, フレディ・マーキュリー) ### 回答: NO ### 入力: 質問:日立製作所と三菱重工業はどちらも会計監査人は同じですか? ### 導出: (日立製作所, 会計監査人, EY新日本有限責任監査法人), (三菱重工業, 会計監査人, 有限責任あずさ監査法人) ### 回答: NO ### 入力: 質問:島津氏と平氏は、どちらも日本の氏族ですか? ### 導出: (島津氏, 出自集団, 武家・華族だった日本の氏族), (平氏, 出自集団, 日本の平姓(たいらのかばね)を持つ氏族) ### 回答: YES ### 入力: 質問:『マツケンサンバ』と『RADIO GA GA』はどちらもミュージックビデオがありますか? ### 導出: (マツケンサンバ, ミュージックビデオ, 【公式】松平健「マツケンサンバⅡ」MV-YouTube), (RADIO GA GA, ミュージックビデオ, 「RADIO GA GA」-YouTube) ### 回答: YES
評価結果
選択式質問応答は選択肢が与えられているので、JCommonsenseQA と同様、exact match で評価しました。 YES・NO の分類も同様です。 加えて自由記述式質問応答でも exact match を採用しました。 これは JEMHopQA の自由記述式質問応答が年月日を訊ねる質問を多く含むからです。 年月日を答える場合、1024年4月1日と 2024年4月1日のように、1文字違いでも致命的な間違いとなります。
先に示したデータセットごとのモデル性能一覧の JEMHopQA の列が exact match の正解率です。 サブタスクごとのスコアは以下に棒グラフで示します。
自由記述式質問応答スコアを棒グラフで表示

選択式質問応答スコアを棒グラフで表示

2値分類(YES・NO)スコアを棒グラフで表示

サブタスクごとに分けて観察すると、モデルごとの得意不得意が見えます。 自由記述式質問応答は Sarashina、Swallow の得意分野ですが、 選択式質問応答や YES・NO の分類になると他の継続事前学習モデルの正解率が高いです。 JCommonsenceQA の結果を踏まえると、 あらかじめ選択肢が決まっている質問では mistral からの継続事前学習モデル RakutenAI-7B や、 Qwen ベースの nekomata-14b が性能を発揮するようです。
以下は 4-shot事例をサブタスク間で共通にした設定とサブタスクごとに設定した場合の評価スコア比較の抜粋です。 タスクに応じた 4-shot事例を作成することで、モデルの能力をより効果的に引き出せることがわかります。
| モデル | 共通 few-shot (exact match) |
サブタスクごとの 4-shot (exact match) |
|---|---|---|
| RakutenAI-7B | 33.33 | 47.01 |
| Sarashina1-7B | 35.83 | 45.30 |
| Sarashina2-7B | 39.17 | 55.56 |
| Sarashina1-13B | 34.17 | 44.44 |
| nekomata-14b | 44.17 | 57.26 |
| Swallow-13b | 36.67 | 62.39 |
| Sarashina2-13B | 43.33 | 64.96 |
| Sarashina1-65B | 38.33 | 60.68 |
| Swallow-70b | 48.33 | 80.34 |
比較表のフルサイズを表示
| モデル | 共通 few-shot (exact match) |
サブタスクごとの 4-shot (exact match) |
|---|---|---|
| calm2-7b | 37.50 | 47.01 |
| RakutenAI-7B | 33.33 | 47.01 |
| Sarashina1-7B | 35.83 | 45.30 |
| Swallow-7b-plus | 40.83 | 52.14 |
| Sarashina2-7B | 39.17 | 55.56 |
| stockmark-13b | 6.67 | 17.95 |
| plamo-13b | 37.50 | 41.88 |
| llm-jp-13b-v2.0 | 34.17 | 47.01 |
| Sarashina1-13B | 34.17 | 44.44 |
| nekomata-14b | 44.17 | 57.26 |
| Swallow-13b | 36.67 | 62.39 |
| Sarashina2-13B | 43.33 | 64.96 |
| karakuri-lm-70b-v0.1 | 37.50 | 52.99 |
| Sarashina1-65B | 38.33 | 60.68 |
| Swallow-70b | 48.33 | 80.34 |
既存評価のツールからの差分
補足として今回我々が JEMHopQA 評価で採用した設定と既存ツール llm-jp-eval v.1.0.0 の設定の差分をまとめます。
- few-shot 事例: llm-jp-eval v1.0.0 ではすべてのサブタスクでタスク種別問わず共通の 4-shot事例を使用。我々はサブタスクごとに異なる 4-shot事例を使用。
- 評価尺度: llm-jp-eval v1.0.0 では char F1、我々は exact match を使用。
- 正規化: llm-jp-eval v1.0.0 では正解とモデルの出力に NFKC 正規化を適用している。我々は NFKC 正規化に加えて、括弧を取り除く処理などを含む正規化を適用。
両設定の評価スコアの比較を示します。全体として大きな傾向の変化は認められませんでした。
llm-jp-eval v1.0.0 の設定と本記事設定の評価値の比較
モデル llm-jp-eval(char F1) 本記事設定(exact match) calm2-7b 49.23 47.01 RakutenAI-7B 45.28 47.01 Sarashina1-7B 47.57 45.30 Swallow-7b-plus 53.75 52.14 Sarashina2-7B 52.43 55.56 stockmark-13b 9.10 17.95 plamo-13b 51.45 41.88 llm-jp-13b-v2.0 48.16 47.01 Sarashina1-13B 49.10 44.44 nekomata-14b 58.99 57.26 Swallow-13b 49.97 62.39 Sarashina2-13B 55.43 64.96 karakuri-lm-70b-v0.1 51.58 52.99 Sarashina1-65B 51.88 60.68 Swallow-70b 62.02 80.34
NIILC-QA
NIILC-QA も AI王と同じ自由記述式質問応答ですが、以下のように正解が複数個ある質問を含みます。
質問:リアス式海岸は日本のどこにある?
回答:三陸海岸の中部から南部,房総半島南部,若狭湾周辺,紀伊半島東部・南部,山陰海岸,宇和海,日豊海岸,日南海岸中部から南部,浅茅湾(長崎県対馬),長崎県九十九島複数個の正解がある場合、モデルにそれらすべてを答えさせるか、1つでも答えられたらよしとするか、何が適切なスコアリングかは自明ではありません。 そこでタスク形式を単純化するため、NIILC-ECQA2015_test.xml (200問)から正解が複数個の質問は一旦除外し、 正解が 1つの質問だけで評価しました(162問)。 llm-jp-eval v.1.0.0 の評価に合わせて固定の 4-shot事例(正解が1つの質問のみに修正)で生成を教示しています。
NIILC-QA で使用した 4-shot事例
以下はタスクを説明する指示と、追加の背景情報を提供する入力の組み合わせです。要求を適切に満たす回答を書いてください。 ### 指示 質問に対する答えを出力してください。 ### 入力: 質問:ワールドカップは何年に一度開催されるの? ### 回答: 4年 ### 入力: 質問:サッカーのイエローカードはいつ出るの? ### 回答: 非紳士的行為等を行ったとき ### 入力: 質問:ハリーポッターの著者は誰? ### 回答: J・K・ローリング ### 入力: 質問:携帯電話の身体に与える影響は? ### 回答: 発がん性のリスクが高まる
評価結果
NIILC-QA も exact mach で評価しました。 先に示したデータセットごとのモデル性能一覧の NIILC の列が exact match のスコアです。 このデータセットでは 70b 規模では Swallow-70b の性能が最も高い結果ですが、 7b、13b 規模では Sarashina2 が最も高い結果となっています。 AI王の評価と合わせると、Sarashira と Swallow は日本の知識を問う自由記述式質問応答を得意としていることがわかります。
NIILC-QA のスコアを棒グラフで表示

JSQuAD
JSQuAD は機械読解のタスクです。 文章が与えられ、その文章に関連した質問に答えます。 評価には valid-v1.1(4,442問)を使用しました。
### 入力:
文章:梅雨 [SEP] 梅雨の時期が始まることを梅雨入りや入梅(にゅうばい)といい、社会通念上・気象学上は春の終わりであるとともに夏の始まり(初夏)とされる。なお、日本の雑節の1つに入梅(6月11日頃)があり、暦の上ではこの日を入梅とするが、これは水を必要とする田植えの時期の目安とされている。また、梅雨が終わることを梅雨明けや出梅(しゅつばい)といい、これをもって本格的な夏(盛夏)の到来とすることが多い。ほとんどの地域では、気象当局が梅雨入りや梅雨明けの発表を行っている。
質問:入梅は何の目安の時期か?
### 回答:
田植えの時期の目安文章から回答を抜き出す動作を 4-shot事例で教示します。
JSQuAD で使用した 4-shot事例
以下はタスクを説明する指示と、追加の背景情報を提供する入力の組み合わせです。要求を適切に満たす回答を書いてください。 ### 指示 質問に対する回答を文章から一言で抽出してください。回答は名詞で答えてください。 それ以外には何も含めないことを厳守してください。 ### 入力: 文章:聖武天皇 [SEP] 文武天皇の第一皇子として生まれたが、慶雲4年6月15日(707年7月18日)に7歳で父と死別、母・宮子も心的障害に陥ったため、その後は長らく会うことはなかった。物心がついて以後の天皇が病気の平癒した母との対面を果たしたのは齢37のときであった。このため、同年7月17日(707年8月18日)、父方の祖母・元明天皇(天智天皇皇女)が中継ぎの天皇として即位した。和銅7年6月25日(714年8月9日)には首皇子の元服が行われて同日正式に立太子されるも、病弱であったこと、皇親勢力と外戚である藤原氏との対立もあり、即位は先延ばしにされ、翌霊亀元年9月2日(715年10月3日)に伯母(文武天皇の姉)・元正天皇が「中継ぎの中継ぎ」として皇位を継ぐことになった。24歳のときに元正天皇より皇位を譲られて即位することになる。 質問:文武天皇の第一皇子として生まれたのは? ### 回答: 聖武天皇 ### 入力: 文章:通称 [SEP] 人名としての通称は通り名、二つ名、異名、などと呼ばれる事もある。近世までは、本名(実名)は「」と呼ばれ、公言は避ける習慣があった。そのため、人を呼ぶ時は「仮名」「字」などの通称、官職名を用いるのが一般的だった。今日でも「総理」「大臣」「社長」「専務」などと呼びかけに使うのがこれにあたる。 質問:人名としての通称は何と呼ばれているか ### 回答: 通り名、二つ名、異名 ### 入力: 文章:坂本龍一 [SEP] 2014年7月10日、所属事務所エイベックス・ミュージック・クリエイティヴから中咽頭癌であること、療養に専念するためにコンサート活動などを中止する旨が発表された。かつてはインタビューなどで度々自身の健康状態や体力に自信を表しており、コンサート等公演スケジュールを自身の健康に起因する理由でキャンセルしたことがなかった。 質問:坂本龍一が療養に専念するためコンサート活動などを中止すると発表したのはいつか。 ### 回答: 2014年7月10日 ### 入力: 文章:リリーフ [SEP] プレッシャーの比較的かからない状態で投げることができるので、若手投手のテストの場としたり、故障明けや登板間隔の開いた投手を調整目的で登板させることもある。敗戦処理であっても好投すれば次回から先発や接戦での中継ぎに起用されるようになる場合もあり、幸い打線の援護を受けてチームが逆転すれば勝利投手に輝くこともある。 質問:打線の援護を受けてチームが逆転するとどんな投手になる? ### 回答: 勝利投手
回答を文章から抜き出すというタスク性質上、その範囲を一意に定められない場合もあります。 そのため JSQuAD は正解を複数用意しています。 上の例の場合、「田植えの時期の目安」「田植えの時期」「春の終わりであるとともに夏の始まり(初夏)」の 3つです。 我々の評価では複数の正解のうちのいずれか 1つでも生成できれば正解としました。
評価結果
JSQuAD も exact match で評価しました。 先に示したデータセットごとのモデル性能一覧の JSQuAD の列が exact match スコアです。 どのサイズのモデルでも総じて高い性能を達成しています。 質問と文章中の正解区間との対応をとる能力は言語に依存しないと考えられるためか、 RakutenAI-7B や nekomata-14b の継続事前学習モデルのスコアが比較的高くなっています。 Sarashina2 は 7b規模では 1位の性能、13b 規模でも大きく差が出ることなく他のモデルに劣らない結果です。
JSQuAD のスコアを棒グラフで表示

他の評価設定との比較
参考までに、既存の評価ツールである llm-jp-eval v1.0.0 の評価結果と我々の評価結果の比較を記載します。 主な違いは以下の通り。
- 正解の数: llm-jp-eval v1.0.0 ではデータセットが用意する正解の中から 1つだけを評価値の計算に使います。我々は複数の正解それぞれとモデル出力の間でスコア(exact match)を算出し、その最大値をその質問でのスコアとします。
- 正規化: llm-jp-eval v.1.0.0 では正解とモデルの出力に NFKC 正規化を適用しています。我々は NFKC 正規化に加えて、括弧を取り除く処理などが入った正規化を用いています。
両者の間で大きな傾向の違いは見られません。
| モデル | llm-jp-eval (char F1) |
llm-jp-eval (exact match) |
本記事設定 (exact match) |
|---|---|---|---|
| calm2-7b | 78.08 | 61.03 | 69.43 |
| RakutenAI-7B | 87.69 | 73.50 | 83.52 |
| Sarashina1-7B | 82.71 | 69.41 | 77.78 |
| Swallow-7b-plus | 85.34 | 72.08 | 81.34 |
| Sarashina2-7B | 88.01 | 75.57 | 85.66 |
| stockmark-13b | 72.56 | 60.72 | 68.53 |
| plamo-13b | 76.14 | 60.33 | 68.46 |
| llm-jp-13b-v2.0 | 81.38 | 67.42 | 76.63 |
| Sarashina1-13B | 82.77 | 68.60 | 78.16 |
| nekomata-14b | 91.44 | 80.05 | 90.03 |
| Swallow-13b | 90.03 | 78.48 | 88.34 |
| Sarashina2-13B | 90.01 | 78.66 | 88.56 |
| karakuri-lm-70b-v0.1 | 90.87 | 79.51 | 88.68 |
| Sarashina1-65B | 87.76 | 75.28 | 85.21 |
| Swallow-70b | 91.74 | 80.80 | 91.00 |
まとめ
本記事では Sarashina の事前学習モデルの性能評価について説明しました。 AI王のような日本の知識を問う自由記述式質問応答では日本語テキストでフルスクラッチ学習した Sarashina が高い性能を発揮します。 選択式質問応答や機械読解のような文脈理解タスクでは継続事前学習モデルが高い性能を発揮しますが、 Sarashina も大きく負けているわけでもありません。 これらを総合して Sarashina が高い平均性能を達成していることがわかりました。
大規模言語モデルの評価には難しい面が多くあり、評価の設計を誤るとモデルの本来の能力を測ることができません。 本記事で述べた知見が参考になれば幸いです。 本ブログに記載している評価内容に関しては、評価用ツール flexeval を使った再現用の設定ファイル・コマンドを公開しています(リンク)。